Week 6 - NLP Project
처음으로 github.io에 주간 학습 정리를 올린다. 회고록도 잘 작성해야 하는데 프로젝트가 시작되고 정신이 하나도 없어서 이번 주는 반성해야겠다….
NLP 문제 종류
NLP 문제는 출력 형태에 따라 N21, N2N, N2M의 총 세 가지 종류로 구분할 수 있다.
N21 문제
감정 분석, 토픽 분석, 함의, 등 classification에 속하는 문제들이 있으며, STS와 같이 최종 score를 출력하는 문제 또한 N21 문제에 속한다.
일반적으로 Encoder를 사용한다. 모든 sequence의 가장 앞에 [CLS] token이 붙는데, 이 token이 Encoder 내에서 주어진 sequence의 모든 token들과 self-attention 연산을 수행하며 관계를 맺는다. 즉, 입력으로 주어진 문장 전체를 압축한 정보를 갖게 된다.
이 [CLS] token의 출력 결과에 Softmax 등을 적용하여 확률 분포로 변환한 뒤 classification을 수행한다. classification이 아닌 경우, $(-\infin, \infin)$의 범위를 $[0, 1]$의 범위로 변환하는 등의 작업을 수행할 수 있다.
N2N 문제
입력으로 주어지는 모든 token에 일대일로 대응하는 token들을 출력하는 문제이다. 품사 태깅과 같이 개체명의 범주를 파악하는 문제들이 여기에 속한다. 이때 범주 파악이 안 되는 경우, Out-of-Distribution으로 표현하여 모든 token에 대해 결과를 출력한다.
입력 sequence 내 각 token이 다른 token들과의 self-attention 연산을 통해 sequence 내에서 어떤 역할을 하는지 파악한다. 이제 각 token별 출력을 N21 문제와 동일하게 softmax를 적용해서 단어로 변환하는 등의 후작업을 거친다.
N2M 문제
입력 sequence에 대한 응답 sequence를 생성하는 생성형 task가 여기에 속하며, 기계 번역, 기계 대화, 요약 등의 task를 예로 들 수 있다. 이때 M은 고정된 숫자가 아니고, 수치적으로는 1, N과 같은 수일 수도 있으나, 같은 task를 의미하지는 않는다.
Encoder-Decoder 구조를 사용할 수도 있으며, 일반적으로는 Decoder 모델을 사용한다. Auto-Regressive한 방식으로 이전 timestep에서 생성한 token을 다시 입력으로 주어 다음 timestep의 token을 출력한다. 추가적으로 이미지에 대한 설명을 출력하는 Image Captioning도 여기에 속하는데, ViT와 같은 모델에서 이미지를 작은 patch로 쪼개서 sequential한 task로 취급이 가능해진다.
NLP 문제 해결 과정
아래 내용을 참고해서 프로젝트 일정 수립에 참고할 수 있다.
텍스트 데이터 처리 및 분석
데이터 수집
웹 크롤링, 벤치마크 데이터셋 탐색 등을 수행한다.
텍스트 데이터 전처리
문법 교정, 불용어 제거 등과 같이 데이터를 정제하고 정규화하는 과정이 필요하다.
특히 정제 과정에서 문법 교정을 할 때, 영화 리뷰 감성 분석과 같은 경우에는 ‘ㅋㅋㅋ’, ‘;;;’과 같이 문법에는 맞지 않지만 의미를 갖는 글자들은 주의해야 한다.
Tokenization
텍스트 데이터를 corpus라 하고, 이 corpus에 있는 sequence data들을 token으로 구분해야 한다. 보통 의미를 가지는 최소 단위를 token이라고 하며, 언어와 모델의 특성에 따라 다른 종류의 tokenizer를 사용하기도 한다. 이전에 공부했던 BPE, WordPiece, Unigram 등의 방법들이 있다.
데이터 분석
통계적으로 라벨별, 소스별 데이터의 분포를 확인한다. 라벨 간 불균형이 발생했을 때 증강을 하거나, train data에 해당 데이터를 포함하게 하는 등의 방법을 적용할 수 있다. 주요 단어를 파악함으로써 수행하고자 하는 task의 특징에 적합한 형태로 가공하는 등 다양한 기법을 포함한다.
모델 선정 및 베이스라인 코드 작성
데이터 분석이 완료된 후에는 해당 데이터의 특성과 task에 맞는 모델을 선정한다. Hugging Face에서 순위가 가장 높은 모델을 선정한다면 당연히 좋겠지만, 순위는 시시각각 바뀌기도 하고 가용 자원을 고려해야 하기 때문에 적절한 분석이 필요하다.
모델을 선정했다면 베이스라인 코드를 작성한다. Hugging Face API, 공식 문서를 참고하면 다양한 모델을 수행하고자 하는 task에 맞게 알아서 불러오는 모듈들이 잘 구현되어 있다. 하지만 많은 분들이 내부 동작과 구현을 알아볼 수 있도록 pytorch 등을 기반으로 공부하고 잘 정리해두기를 추천하신다.
성능 분석 및 성능 향상 기술 적용
성능 분석
모델의 성능을 분석하기 위해서는 일반적으로 metrics를 활용한다.
classification같은 경우 accuracy와 recall을 모두 고려한 f1-score를 활용하고, 생성형의 경우 몇 개의 단어가 정답과 일치하는지 판단하는 BLEU score를 활용하는 등 task마다, 출력의 형태마다 다른 metrics를 적용한다.
또한 통계적으로 유의미한 결과라는 것을 검증하기 위해 두 그룹 간의 평균의 차이를 보는 T-value, T-value가 발생할 확률인 P-value, 두 그룹 간의 상관관계(correlation) 등을 사용한다.
이 외에도 자연어 분야에서는 transformer를 쓴느 만큼, attention map과 같은 시각화 자료를 사용할 수도 있다. 다만 이 방법은 모델이 self-attention을 어떻게 연산했는지 사람이 이해할 수 있도록 시각화 한 것일 뿐, 모델의 정확도 자체를 나타내는 지표는 아니다.
성능 향상
모델의 학습률, 배치 사이즈 등을 조정하는 하이퍼파라미터 최적화를 적용할 수 있다. optuna, wandb의 sweep과 같은 모듈을 사용할 수도 있지만, Bayesian Optimization과 같은 방법론도 사용해볼 수 있다.
또한 여러 모델의 결과 중 다수결을 따르는 Voting, 전체 데이터셋에서 랜덤 샘플링한 데이터로 여러 모델을 학습하여 투표하는 Bagging, 모델이 잘 못하는 부분에 대해서만 재학습하는 Boosting 등의 방법들을 적용할 수도 있다.
Parameter Efficient Fine Tuning
최근 LLM이 유행(후…)하면서 task specific하게 만들고자 fine-tuning을 시도하는 방법이 늘고 있다. prompt based 방법들도 많지만 fine tuning 또한 많이 사용되는 방법인데, 그 거대한 모델을 과연 어떻게 fine-tuning 할 것인가!?
이때 바로 PEFT라고 하는 Parameter Efficient Fine Tuning 방법이 적용된다.
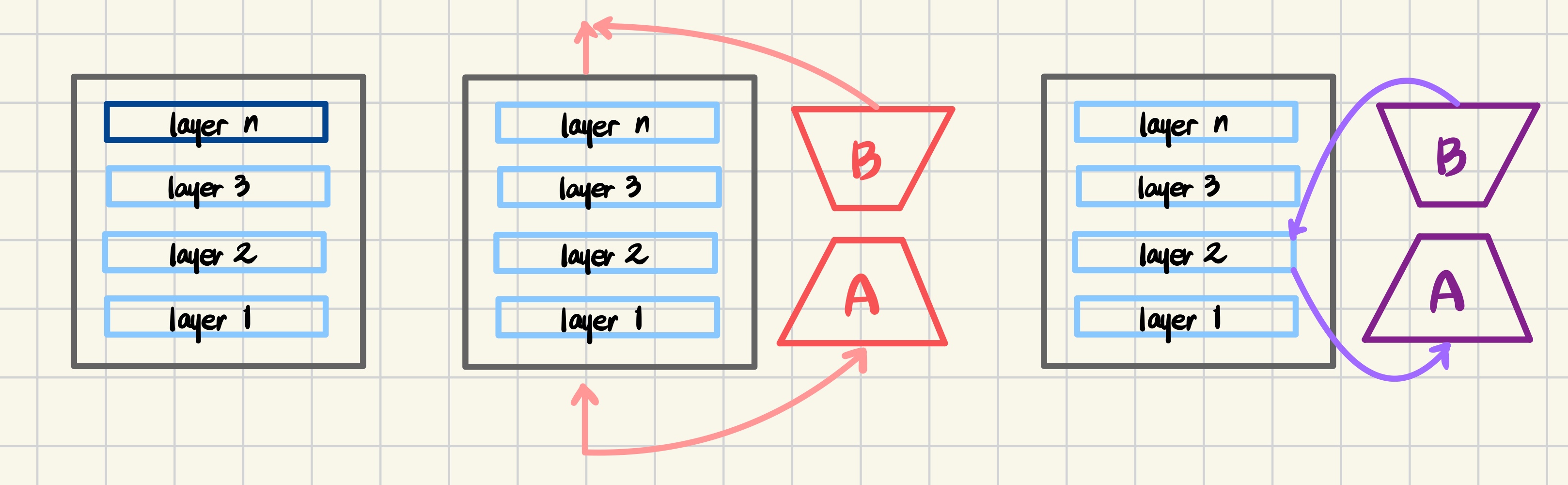
왼쪽부터 순서대로 일부 레이어 튜닝,파라미터 보정, 은닉층 보정 방식이다.
Prefix Tuning
일부 레이어를 튜닝할 때 가장 끝단에 레이어를 추가로 두어 이 레이어만 학습한다. BERT와 같은 구조이다.
LoRA
Low Rank Adaptation의 줄임말이다. 사전 학습된 모델의 param들은 freeze하고, 모델의 대리인 역할을 하는(위 사진의 A, B) 외부 param들만 빠르게 학습한다.
ReFT
Representation Fine-Tuning의 줄임말고, 앞서 말한 LoRA와 다르게 지정된 위치의 은닉층의 값을 조정한다. LoRA와 함께 적용되기도 한다.
그런데 여기서 궁금한 점은.. 지정된 위치의 은닉층의 param을 조정하는 것과 이 외부 레이어를 보정하는 것에 차이가 있나..? 역전파를 할 때 모든 레이어를 거치지 않아도 된다는 장점이 있겠지만, 실제로 LoRA와 비교하여 굳이 ReFT를 써야 하는 이유는 잘 모르겠다.